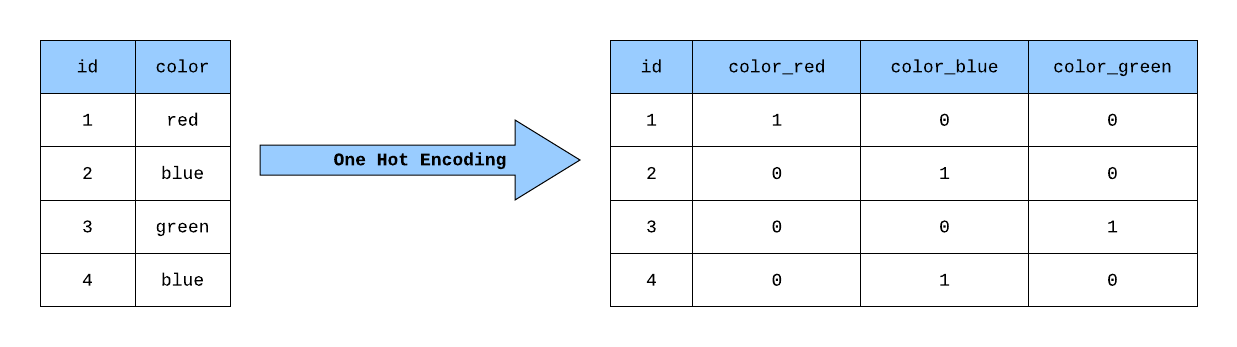
원핫 인코딩(One-hot Encoding)이란?
원핫 인코딩(One-hot Encoding)은 범주형 데이터(Categorical Data)를 이진화된 값(Binary Value)으로 변환하는 방법입니다.
텍스트 데이터를 머신러닝 모델에 입력하기 위해 숫자로 바꿔야 하는데, 이때 단순히 정수형 라벨로 변환하면 모델이 범주 간의 순서나 크기를 잘못 해석할 수 있습니다.
이를 방지하기 위해 원핫 인코딩을 사용합니다.
왜 원핫 인코딩을 사용할까?
범주형 데이터는 순서가 없고 크기 비교가 불가능한 값들입니다.
예를 들어, “개”, “고양이”, “말”이라는 세 가지 카테고리가 있다면, 이를 단순히 정수형 라벨로 변환하면 다음과 같이 표현할 수 있습니다.
정수형 라벨 인코딩 (Integer Label Encoding) 예시
"개" = 1, "고양이" = 2, "말" = 3그러나 정수형 라벨은 머신러닝 모델이 범주 간의 순서나 크기가 있다고 잘못 해석할 수 있습니다.
즉, 모델이 “개” < “고양이” < “말”이라고 이해할 수 있습니다.
이를 방지하고 각 범주가 서로 독립적임을 나타내기 위해 원핫 인코딩을 사용합니다.
원핫 인코딩(One-hot Encoding) 예시
원핫 인코딩은 각 범주를 고유한 이진 벡터로 변환합니다.
각 벡터는 해당 범주를 나타내는 인덱스만 1이고, 나머지는 0으로 표현됩니다.
예시: “개”, “고양이”, “말”
"개" → [1, 0, 0] "고양이" → [0, 1, 0] "말" → [0, 0, 1]이때, 각 인덱스는 다음과 같은 의미를 가집니다.
- [1, 0, 0] → 첫 번째 카테고리 “개”
- [0, 1, 0] → 두 번째 카테고리 “고양이”
- [0, 0, 1] → 세 번째 카테고리 “말”
이렇게 변환하면 범주 간의 순서나 크기 관계가 사라지며, 각 범주는 서로 독립적이라는 특징을 유지합니다.
scikit-learn을 활용한 원핫 인코딩(One-hot Encoding)
관련 import
from numpy import array
from numpy import argmax
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
예제 데이터 설정
data = ['cold', 'cold', 'warm', 'cold', 'hot', 'hot', 'warm', 'cold', 'warm', 'hot']
print(set(data))
values = array(data)
print(values)
결과
{'hot', 'cold', 'warm'}
['cold' 'cold' 'warm' 'cold' 'hot' 'hot' 'warm' 'cold' 'warm' 'hot']Integer Encoding
label_encoder = LabelEncoder()
integer_encoded = label_encoder.fit_transform(values)
print(integer_encoded)
결과
[0 0 2 0 1 1 2 0 2 1]One-hot Encoding
onehot_encoder = OneHotEncoder(sparse_output=False)
integer_encoded = integer_encoded.reshape(len(integer_encoded), 1)
print(integer_encoded.reshape(len(integer_encoded), 1))
print(integer_encoded.shape)
onehot_encoded = onehot_encoder.fit_transform(integer_encoded)
print(onehot_encoded)
결과
[[0]
[0]
[2]
[0]
[1]
[1]
[2]
[0]
[2]
[1]]
(10, 1)
[[1. 0. 0.]
[1. 0. 0.]
[0. 0. 1.]
[1. 0. 0.]
[0. 1. 0.]
[0. 1. 0.]
[0. 0. 1.]
[1. 0. 0.]
[0. 0. 1.]
[0. 1. 0.]]
다시 string 형태로 변경
inverted = label_encoder.inverse_transform([argmax(onehot_encoded[0, :])])
print(inverted)
결과
['cold']
원핫 인코딩의 문제
원핫 인코딩 벡터의 크기
원핫 인코딩 벡터의 크기는 **어휘 집합(Vocabulary Set)**의 크기와 같습니다.
예를 들어, 어휘 집합에 10,000개의 단어가 있다면, 각 단어는 길이가 10,000인 벡터로 표현됩니다.
예시: 어휘 집합의 크기가 10,000일 때
"사람" = [0, 0, 0, ..., 1, ..., 0, 0, 0]- 10,000개의 원소 중 **"사람"**에 해당하는 인덱스만 1이고, 나머지 9,999개는 0입니다.
희박(Sparse)한 벡터 문제
원핫 인코딩은 다음과 같은 문제점이 있습니다.
1. 벡터가 희박(Sparse)해짐
- 어휘 집합이 클수록 대부분의 원소가 0으로 채워지며, 1은 하나만 존재
- 예: 어휘 집합 크기가 10,000일 때, 9,999개의 0와 1개의 1로 구성
2. 차원의 저주(Curse of Dimensionality)
- 벡터의 차원이 커질수록 모델의 메모리 사용량과 연산 비용이 크게 증가
- 학습 속도가 느려지고 과적합(Overfitting) 위험이 높아짐
한계점
- 단어 간의 관계(유사도)를 반영하지 못함
- "개"와 "고양이"가 비슷한 의미를 가지더라도 벡터 간 코사인 유사도가 0
- 대규모 어휘 집합에서는 비효율적
대안: 임베딩(Embedding)
이 문제를 해결하기 위해 등장한 것이 단어 임베딩(Word Embedding)입니다.
- Word2Vec, GloVe, FastText 등 벡터화 기법 사용
- 단어를 저차원의 밀집(Dense) 벡터로 표현하여 단어 간 유사도를 반영
- 예: "개"와 "고양이"의 임베딩 벡터가 서로 가까운 값으로 표현
'AI > Basic NLP' 카테고리의 다른 글
| NLTK를 활용한 N-GRAM 언어 모델 (0) | 2025.03.01 |
|---|---|
| NLTK를 활용한 Tokenizing (0) | 2025.02.27 |