마스터 노드와 워커(slave) 노드

마스터 노드
: 클러스터의 작업을 중재, 클라이언트들이 실제로 컴퓨팅을 하기 위해 접속하는 노드 , 3~6개 정도로 구성
- 네임노드 (NameNode): 마스터 노드 중 하나는 네임노드로 역할을 수행합니다. 네임노드는 메타데이터를 관리하고, 데이터 블록의 위치를 추적합니다. 클라이언트 요청에 대한 응답으로 데이터 블록을 검색하고 조정하여 데이터의 신뢰성과 가용성을 제공합니다.
- 잡 트래커 (JobTracker): 마스터 노드의 다른 주요 구성 요소는 잡 트래커입니다. 잡 트래커는 사용자가 제출한 작업을 관리하고 클러스터 내의 워커 노드에 할당하여 작업을 실행합니다. 작업의 진행 상황을 모니터링하고 실패한 작업을 다시 할당하여 장애 복구를 수행합니다.
- 보조 네임노드 (Secondary NameNode): 보조 네임노드는 네임노드의 백업 역할을 수행하며, 주기적으로 네임노드의 파일 시스템 이미지와 트랜잭션 로그를 복사하여 데이터의 일관성을 유지합니다.
워커 노드
: 마스터노드들의 지실르 따라서 명령을 수행함, 실제로 데이터 저장되고 프로세싱하는 노드
- 데이터노드 (DataNode): 워커 노드 중 하나는 데이터노드로 역할을 수행합니다. 데이터노드는 데이터 블록을 저장하고 관리합니다. 네임노드의 요청에 따라 데이터 블록을 읽거나 쓰는 작업을 수행합니다. 데이터의 복제와 신뢰성을 제공하기 위해 데이터 블록을 다른 데이터노드로 복제할 수도 있습니다.
- 태스크 트래커 (TaskTracker): 워커 노드의 다른 주요 구성 요소는 태스크 트래커입니다. 태스크 트래커는 잡 트래커로부터 할당받은 작업을 수행합니다. 이 작업은 맵(Map) 단계와 리듀스(Reduce) 단계로 나누어지며, 데이터를 처리하고 중간 결과를 생성하여 전송합니다.
워커 노드들은 여러 대의 머신으로 구성된 하둡 클러스터에서 작업을 분산하고 데이터를 처리하여 빠른 처리 속도와 고 가용성을 제공합니다. 마스터 노드는 클러스터의 전반적인 제어와 관리를 수행하여 클러스터의 안정성과 성능을 유지합니다.
데이터 스토리지
HDFS
- HDFS는 하둡 클러스터에서 대용량의 데이터를 안정적으로 저장하고 처리하기 위한 분산 파일 시스템
- HDFS는 데이터를 여러 개의 블록으로 분할하고, 여러 대의 머신에 분산하여 저장. 이러한 분산 저장은 데이터의 안정성과 가용성을 제공
- 데이터 복제를 통해 장애 복구 기능을 갖추고 있음 ( 각각의 데이터 블록이 3개의 다른 노드에 저장됨)
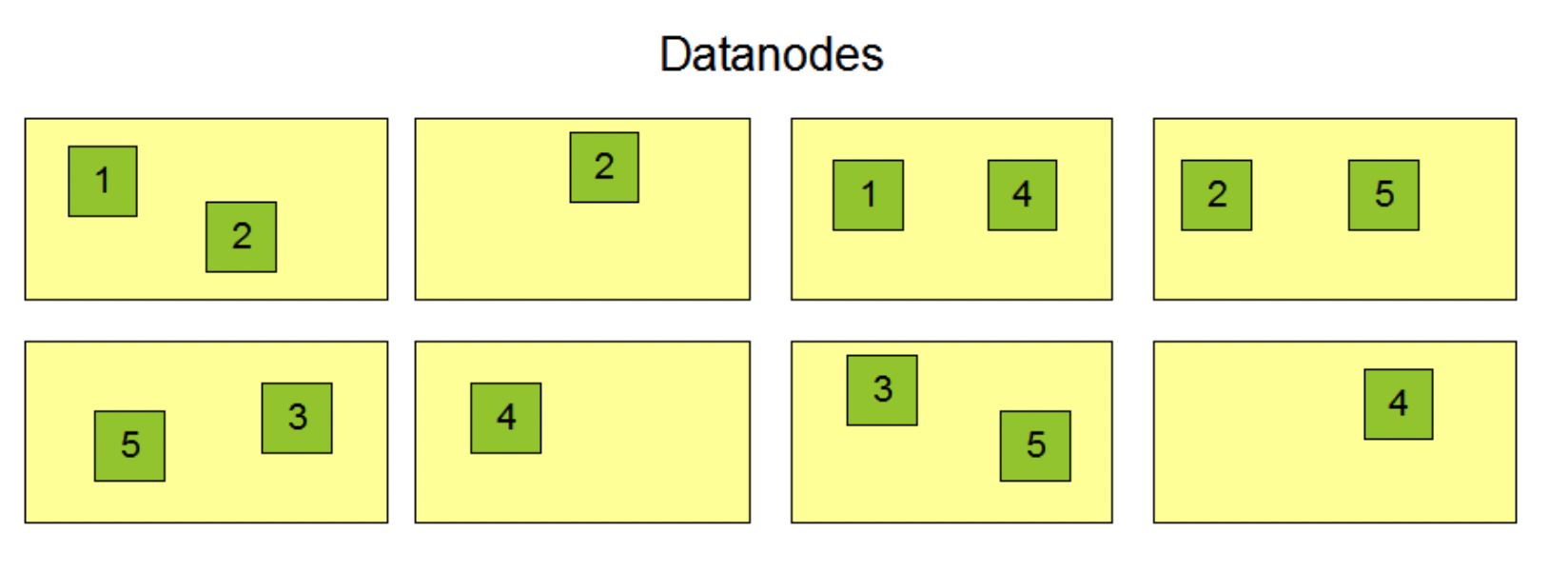
- HDFS는 일괄 처리 작업에 적합하며, 대용량 데이터의 저장과 검색에 사용
- 일반적인 RDBMS보다 훨씬 큰 블록을 사용함( 오라클의 경우 8kb, 하둡의 경우 128mb가 기본)
네임노드와 데이터노드
- 하둡클러스터 내의 하나 이상의 마스터노드에 있는 네임노드들은 워커 노드에 있는 데이터 노드들을 통해 데이터를 관리합니다.
- 보통은 노드 매니저 (YARN)을 통해서 실행합니다.

네임노드와 데이터노드를 통한 실제 Read과정
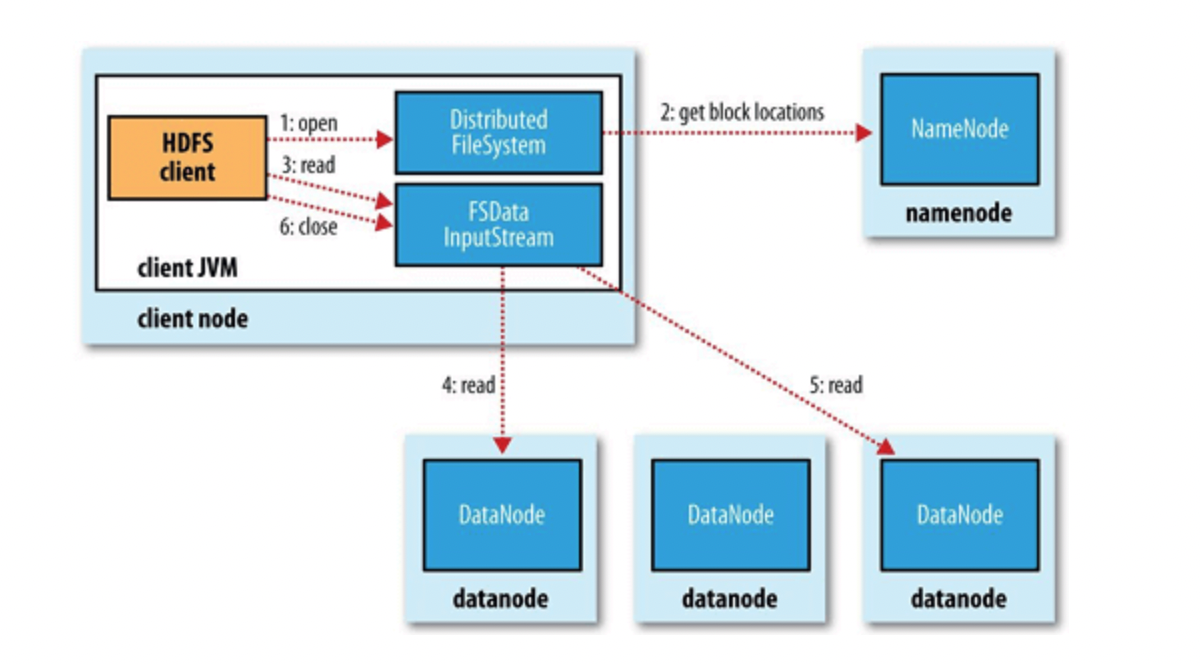
- 클라이언트는 네임노드에 접속하여 원하는 데이터가 존재하는 블록의 위치를 묻는다
- 클라이언트는 해당응답을 통해 특정한 데이터 노드에 접속하여 데이터를 가져옴
- 만약 노드의 블록이 깨져 있다면, 네임노드에게 이를 전달하고 다른 블록을 참조
네임노드와 데이터노드를 통한 실제 write과정

- 클라이언트 요청: 클라이언트가 파일을 생성하거나 기존 파일에 데이터를 추가하기 위해 Write 작업을 요청.
- 네임노드 처리: 네임노드는 해당 파일의 메타데이터를 확인하고 어떤 데이터노드에 블록을 저장할지 결정.
- 데이터노드 할당: 네임노드는 Write 요청을 받은 데이터노드에게 블록을 저장할 수 있도록 할당. (데이터노드는 클라이언트와 직접 통신)
- 데이터 전송: 클라이언트는 실제 데이터를 작은 조각인 데이터 패킷(Packet)으로 분할하여 데이터노드에 전송
- 데이터 저장: 데이터노드는 수신한 데이터 패킷을 디스크에 저장. 이때, 데이터 패킷은 임시로 디스크의 로컬 파일 시스템에 저장되며, 이후 블록 단위로 HDFS에 저장.
- 복제: 데이터노드는 네임노드의 지시에 따라 블록의 복제를 수행.
- 확인 응답: 데이터노드는 데이터 블록을 저장한 후, 네임노드에게 작업이 완료되었음을 확인하는 응답을 보냄.
- 메타데이터 갱신: 네임노드는 블록이 저장된 데이터노드의 정보와 블록의 위치 정보를 갱신하여 파일의 메타데이터를 업데이트
HDFS 데이터 형식
- 하둡에서 표준 데이터 스토리지 포맷은 존재하지 않는다.
- 텍스트, 바이너리, 이미지와 같은 다양한 포맷으로 저장 가능하다.
- 보다 효율적인 데이터 스토리지를 구성하기 위해서 데이터 스토리지 옵션 사항을 결정한다.
AVRO
AVRO는 데이터 직렬화 및 데이터 기록에 사용되는 오픈 소스 데이터 형식입니다.
스키마 기반으로 데이터를 저장하며, 스키마는 JSON 형태로 정의됩니다.
동적 스키마 지원으로 유연한 데이터 모델링이 가능합니다.
압축 기능과 데이터의 직렬화/역직렬화를 위한 코드 생성 기능을 제공합니다.
다양한 프로그래밍 언어에서 지원되고, 하둡 에코시스템과 통합하여 사용할 수 있습니다.
ORC (Optimized Row Columnar)
ORC는 Apache Hive에서 사용하는 칼럼 지향 데이터 파일 형식입니다.
컬럼 지향 형식으로 데이터를 저장하여, 필요한 칼럼만 읽어오는 경우 I/O 성능을 향상합니다.
압축 기능을 포함하여 저장 공간을 절약하고, 직렬화/역직렬화 작업을 최적화합니다.
특히 대량의 정형화된 데이터를 쿼리 하는 데 효율적이며, Hive 및 다른 하둡 기반 도구와 호환됩니다.
Parquet
Parquet은 Apache Hadoop, Apache Spark 등 다양한 하둡 기반 시스템에서 사용되는 칼럼 지향 데이터 파일 형식입니다.
컬럼 지향 구조로 데이터를 저장하여 압축률을 향상하고, 필요한 칼럼만 읽어오는 경우 I/O 성능을 최적화합니다.
스키마를 유지하며, 스키마 진화를 지원합니다.
다양한 프로그래밍 언어와 하둡 생태계의 도구와 호환됩니다.
범용적으로 사용되는 데이터 형식으로, 대용량 데이터 처리 및 분석에 널리 사용됩니다.
HDFS의 HA
Secondary NameNode
: 체크포인트를 통한 네임노드 부하 감소와 백업 역할

1. 네임노드의 상태 수집:
세컨더리 네임노드는 주기적으로 네임노드의 상태 정보를 수집합니다.
네임노드의 메모리 상태와 파일 시스템 이미지(fsimage)를 수집합니다.
* fsimage : 네임노드의 파일시스템 스냅숏
네임노드는 이러한 상태 정보를 주기적으로 세컨더리 네임노드로 전송합니다.
2. 로그 복사:
세컨더리 네임노드는 네임노드의 저널 로그(edit log)를 복사합니다.
저널 로그는 네임노드와 데이터노드(DataNode) 간의 통신 중에 발생하는 파일 시스템 변경 작업을 기록하는 로그입니다.
세컨더리 네임노드는 주기적으로 네임노드로부터 저널 로그를 전달받아 로그 복사 작업을 수행합니다.
3. 체크포인트 생성:
세컨더리 네임노드는 수집한 네임노드의 상태 정보와 복사한 저널 로그를 사용하여 체크포인트를 생성합니다.
체크포인트는 네임노드의 메모리 상태와 파일 시스템 이미지의 스냅샷으로, 장애 복구 시 사용됩니다.
체크포인트 생성은 네임노드의 부하를 줄이고, 네임노드 장애 발생 시 초기 상태를 복구하는 데 도움을 줍니다.
4. 체크포인트 전송:
세컨더리 네임노드는 생성한 체크포인트를 네임노드로 전송합니다.
네임노드는 해당 체크포인트를 이용하여 장애 발생 시 자신의 상태를 복구할 수 있습니다.
StandBy NameNode
: 네임노드의 백업 역할을 수행.

- 네임노드와 동일한 메타데이터 정보를 유지하며, 실시간으로 업데이트되는 저널 로그(edit log)를 수신하여 동기화.
- 네임노드에 장애가 발생하면 스탠바이 네임노드는 네임노드의 역할을 대신 수행하여 서비스의 지속성을 유지.
- 스탠바이 네임노드는 네임노드 장애가 발생한 경우 자동으로 활성화되는 자동 장애 복구 기능을 제공.
'Tools > Hadoop' 카테고리의 다른 글
| 하둡 클러스터와 리소스 할당 (0) | 2023.09.26 |
|---|---|
| 하둡 네임노드와 HDFS (0) | 2023.09.11 |
| MapReduce 이해 하기 (0) | 2023.07.25 |
| Hadoop YARN 아키텍쳐 (0) | 2023.07.02 |
| Hadoop 컴퓨팅과 클러스터 (0) | 2023.07.02 |