Spark 메모리 사용 예시
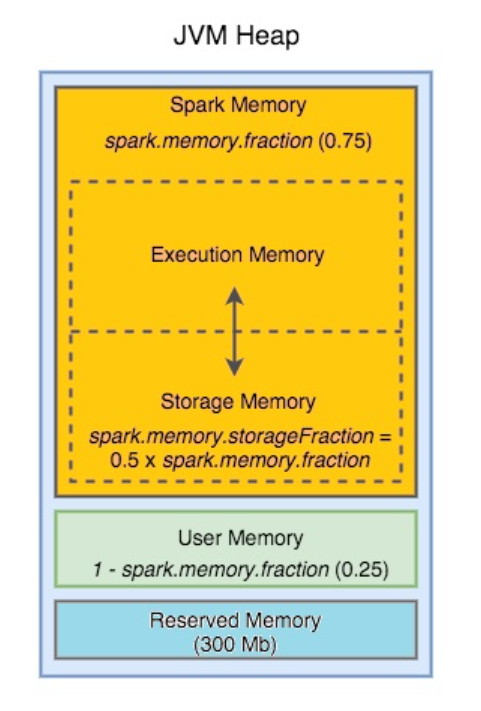
매개변수설명
| spark.memory.fraction (기본값 0.75) | 실행 및 저장에 사용되는 힙 공간의 비율입니다. 이 값이 낮을수록 유출 및 캐시된 데이터 제거가 더 자주 발생합니다. 이 구성의 목적은 내부 메타데이터, 사용자 데이터 구조 및 희소하고 비정상적으로 큰 레코드의 경우 부정확한 크기 추정을 위한 메모리를 따로 확보하는 것입니다. |
| spark.memory.storageFraction (기본값 0.5) | spark.memory.fraction 에 의해 따로 설정된 공간 내 저장 영역의 크기입니다 . 캐시된 데이터는 총 스토리지가 이 영역을 초과하는 경우에만 제거될 수 있습니다. |
1. spark.excutor.memory 프로퍼티에 4GB 설정된 상황(4096)
2. 시작 전에 예약 메모리로 300mb를 제외 (4096-300=3796)
3. spark.memory.fraction 이 0.75 이므로 (3796*0.75 = 2847)
4. spark.memory.storageFraction이 0.5 이므로 절반을 빼면 (2847*0.5 = 1423.5)
익스큐터에 남아있는 1423.5가 애플리케이션 코드를위해 사용가능하다.
익스큐터와 태스크 수
보통, 큰 익스큐터가 적은 수로 있는것이 네트워크 비용을 줄일 수 있기 때문에 효율적
대신 익스큐터당 코어수를 5,6개로 하더라도 동시에 실행되는 태스크가 5,6개가 되기 때문에 큰 이득은 얻지 못한다.
또한 너무 많은 쓰레드도 I/O문제에 직면할 수 있다.
다음과 같은 경우에 여러개의 태스크에서 브로드 캐스트 변수를 공유 할 수 있다.
from pyspark import SparkContext
sc = SparkContext("local", "example")
data = [1, 2, 3, 4, 5]
broadcast_data = sc.broadcast(data)
def process_data(x):
# 브로드캐스트된 데이터 사용
data_list = broadcast_data.value
return x * sum(data_list)
rdd = sc.parallelize([1, 2, 3, 4, 5])
result = rdd.map(process_data)익스큐터와 메모리 사용 사이에는 중요한 트레이드 오프(Trade-off)가 있다.
- 익스큐터 개수와 크기:
- 작은 익스큐터: 작은 익스큐터를 사용하면 클러스터에 많은 익스큐터를 생성할 수 있어 병렬 처리가 가능하지만, 각 익스큐터의 메모리가 작아서 큰 작업을 처리하기 어려울 수 있습니다. 이로 인해 셔플이 더 자주 발생할 수 있습니다.
- 큰 익스큐터: 큰 익스큐터를 사용하면 한 번에 많은 데이터를 처리할 수 있어 대규모 작업에 유리하지만, 클러스터의 총 익스큐터 수가 제한적일 수 있습니다.
- 메모리 할당:
- 적은 메모리: 익스큐터에 적은 메모리를 할당하면 더 많은 익스큐터를 생성할 수 있어 병렬 처리를 강화할 수 있지만, 메모리 부족으로 작업이 실패할 수 있습니다.
- 많은 메모리: 익스큐터에 많은 메모리를 할당하면 단일 작업의 처리량을 향상시킬 수 있지만, 클러스터에서 실행 가능한 익스큐터 수가 줄어들 수 있습니다.
- 효율성:
- 작은 익스큐터 및 적은 메모리를 사용하면 메모리 사용 효율성이 향상되고 병렬성이 높아질 수 있습니다.
- 큰 익스큐터 및 많은 메모리를 사용하면 개별 작업의 처리 속도가 향상되지만 클러스터 전체에서 익스큐터 수가 제한적이므로 병렬성이 감소할 수 있습니다.
- 셔플 처리:
- 셔플 작업은 익스큐터 간의 데이터 이동을 필요로 하며, 메모리 부족이나 작은 익스큐터 크기는 셔플 작업을 더 자주 유발할 수 있습니다.
(예시)
- 클러스터에는 총 4대 노드가 있습니다.
- 각 노드는 16GB의 메모리와 4개의 CPU 코어를 가지고 있습니다.
- 애플리케이션은 데이터셋을 메모리에 캐시하고, CPU 집약적인 처리 작업을 수행합니다.
이러한 상황에서 최적의 익스큐터 크기와 메모리 할당을 결정하기 위한 방법은 다음과 같습니다:
- 클러스터의 총 메모리 고려:
- · 4대의 노드 각각이 16GB의 메모리를 가지고 있으므로 총 64GB의 메모리가 사용 가능합니다.
- 익스큐터 수 결정:
- · 예를 들어, 4개의 익스큐터를 사용하려면 각 익스큐터에는 (64GB / 4) = 16GB의 메모리를 할당할 수 있습니다.
- 메모리 할당과 CPU 코어 할당:
- · 각 익스큐터에 16GB의 메모리를 할당하고 1개의 CPU 코어를 사용할 수 있습니다. 이러한 설정은 각 익스큐터가 충분한 메모리를 가지고 있으며 CPU를 사용하여 처리 작업을 수행할 수 있도록 해줍니다.
- 메모리 및 CPU 사용량 모니터링:
- · 애플리케이션을 실행하고 모니터링하여 메모리 및 CPU 사용량을 확인하고 애플리케이션의 요구에 따라 조정할 수 있습니다. 만약 메모리 부족이 발생한다면 익스큐터에 더 많은 메모리를 할당할 수 있습니다.
이러한 설정은 단순한 예시이며, 애플리케이션의 특성, 데이터셋 크기 및 클러스터 리소스에 따라 다를 수 있습니다. 애플리케이션의 요구사항과 클러스터의 상태를 고려하여 적절한 익스큐터 크기 및 메모리 할당을 결정하는 것이 중요합니다.
다수의 작은 executor VS. 소수의 큰 executor?
다수의 작은 executor의 두가지 문제
- *하나의 파티션을 처리할 자원이 충분하지 않을 수도 있다.
*하나의 파티션이 여러개의 executor에서 계산될 수는 없다. 따라서 셔플, skewed 데이터의 캐시, 복잡한 연산의 transformation 수행 시 OOME 또는 disk spill이 생길 수 있다. - *자원의 효율적 사용이 힘들다.
*같은 노드내 executor끼리 통신에도 약간의 비용이 필요하다.
1GB executor를 갖고 있는 경우 연산을 제외한 오버헤드에만 250MB, 거의 25% 수준의 공간을 써야할 수도 있다.
따라서 자원이 허용된다면, executor는 최소 4GB 이상으로 설정하는 것을 추천한다.
소수의 큰 executor의 두가지 문제
- 너무 큰 executor는 힙 사이즈가 클 수록 GC가 시작되는 시점을 지연시켜 Full GC로 인한 지연이 더욱 길어질 수 있다.
- executor당 많은 수의 코어를 쓰면 동시 스레드가 많아지면서 스레드를 다루는 HDFS의 제한으로 인해 성능이 더 떨어질 수도 있다.
Sandy Ryza(Advanced Analytics with Spark의 저자)는 executor당 5개의 코어를 최대로 보아야 한다고 제안한다.(https://blog.cloudera.com/how-to-tune-your-apache-spark-jobs-part-2/)
예시)
6개의 노드 , 각노드에는 72G 메모리와 코어 16개, 오버헤드고려하여 yarn에 64G 메모리 할당
--num-excutors 6(노드당 1개의 익스큐터)
--executor-cores 15
--executor-memory 60g- 익스큐터당 코어 15개는 너무 많다. I/O문제가 발생할 가능성이 높아진다.
--num-excutors 90(노드당 15개의 익스큐터)
--executor-cores 1
--executor-memory 4g- 익스큐터가 너무 많다.
- 하나의 JVM이 수행하는 태스크가 너무 없어진다.
- 브로드캐스트 변수를 쓰면 복제본이 많아진다. (사실상 필요없는 데이터 중복)
--num-excutors 17(노드 5는 익스큐터3개 , 1개는 2개)
--executor-cores 5
--executor-memory 19g- 적절하다
- 계산해보면 서버당 yarn은 64g
- 초기실행은 64/3 = 21g
- 오버헤드 0.07을 빼면 21*0.93 = 19.53
작업 종류와 리소스 할당
- 배치 처리 작업:
- 리소스 할당: 배치 처리 작업은 대량의 데이터를 처리하므로 많은 메모리 및 CPU 리소스를 필요로 합니다. 메모리에 데이터를 로드하고 효율적으로 처리해야 합니다. 저장을 위한 메모리가 특별히 필요 없는 경우가 많으므로 storageFraction을 0으로 설정 가능하다.
- 추천 설정: Spark의 설정 파일 (예: spark-defaults.conf)을 사용하여 익스큐터 메모리 및 CPU 코어 수를 조정합니다. 배치 작업을 위해 큰 익스큐터 및 메모리를 할당하면 성능이 향상됩니다.
- 셔플 작업:
- 리소스 할당: 셔플 작업은 대용량 데이터의 섞임 및 재분배를 필요로 하므로 메모리와 CPU를 많이 사용합니다. 셔플 파일은 디스크에 저장되기도 합니다.
- 추천 설정: 셔플 관련 설정을 조정하여 메모리와 디스크 사용을 최적화합니다. 예를 들어, spark.shuffle.memoryFraction 및 spark.shuffle.spill 관련 설정을 사용합니다.
- 인터랙티브 쿼리 작업:
- 리소스 할당: 인터랙티브 쿼리 작업은 빠른 응답 시간을 필요로 하므로 작업이 빠르게 처리되어야 합니다. 빠른 응답을 위해 CPU 및 메모리가 중요합니다. 캐시를 통해 큰 이득을 얻을 수 있습니다.
- 추천 설정: 낮은 지연시간을 유지하기 위해 높은 우선순위의 익스큐터를 사용하고 익스큐터 오버헤드를 최소화하는 설정을 사용합니다.
- 머신러닝 및 그래프 처리 작업:
- 리소스 할당: 머신러닝 및 그래프 처리 작업은 반복적인 알고리즘을 수행하므로 CPU 및 메모리 리소스가 중요합니다.
- 추천 설정: 알고리즘의 복잡성에 따라 익스큐터 수 및 메모리 할당을 조정합니다. 모델 훈련과 예측을 위해 메모리를 할당하고 모델 크기에 따라 조정합니다. spark.driver.memory =3g처럼 원하는 메모리를 지정해서 임의로 메모리를 늘리는것도 가능합니다.
데이터 포멧과 압축 고려
- CSV (Comma-Separated Values):
- CSV는 텍스트 기반의 데이터 포맷으로, 데이터를 쉼표(,)로 구분하는 형식입니다. 각 행은 레코드를 나타내고, 각 열은 필드를 나타냅니다. CSV는 읽기 및 쓰기가 간편하며 다양한 응용 프로그램에서 지원됩니다.
- JSON (JavaScript Object Notation):
- JSON은 데이터 교환을 위한 경량의 텍스트 기반 데이터 형식입니다. 데이터는 키-값 쌍으로 표현되며, 중첩된 구조를 지원합니다. JSON은 읽기 가능하며, 다양한 프로그래밍 언어에서 파싱하고 생성할 수 있어 데이터 교환 및 설정 파일 형식으로 널리 사용됩니다.
- Avro:
- Avro는 JSON 기반의 데이터 직렬화 포맷입니다.
- 스키마는 JSON으로 정의되며, 스키마는 데이터와 함께 저장되어 있습니다.
- 압축이 가능하며, 다양한 프로그래밍 언어에서 지원됩니다.
- Avro는 레코드 지향이며, 하나의 파일에 여러 레코드를 저장할 수 있습니다.
- Avro 데이터는 스키마와 함께 저장되어 있어 스키마의 변화에 유연하게 대응할 수 있습니다.
- Parquet:
- Parquet은 columnar 데이터 형식으로, 데이터를 열(Column) 기반으로 저장합니다.
- 압축 및 통계 정보를 활용하여 쿼리 성능을 최적화합니다.
- 대규모 데이터셋을 분석하는 데 효과적이며, 대부분의 빅데이터 프레임워크에서 지원됩니다.
- Parquet는 Hadoop, Apache Spark 및 Apache Hive와 통합되어 있어 사용하기 편리합니다.
- ORC (Optimized Row Columnar):
- ORC도 columnar 데이터 형식이며, Apache Hive와 밀접한 관련이 있습니다.
- 데이터를 열 기반으로 저장하고 압축 및 통계 정보를 활용하여 쿼리 성능을 최적화합니다.
- ORC는 Hive 및 Presto와 같은 분석 도구에서 사용됩니다.
- ORC는 Parquet와 비슷한 목적으로 사용되지만, Hive 및 Presto 사용 시에 사용될 때 성능 향상을 제공할 수 있습니다.
- SequenceFiles:
- SequenceFiles는 Hadoop에서 사용되는 일반적인 데이터 파일 형식으로, 키와 값 쌍을 저장합니다.
- 일반적으로 텍스트 또는 이진 데이터를 저장할 수 있으며, 압축을 지원합니다.
- SequenceFiles는 텍스트 데이터를 저장하는 데 유용하지만, columnar 형식과 비교하면 분석 작업에서 성능 측면에서 제한이 있을 수 있습니다.
'Tools > Spark' 카테고리의 다른 글
| RDD의 생성과 데이터 처리 (1) | 2024.03.11 |
|---|---|
| 스파크 클러스터 동작방식 (0) | 2024.03.07 |
| Spark 클러스터 환경 구성과 실행 (0) | 2024.02.19 |
| 빅데이터, 하둡 및 Spark 소개 (0) | 2024.02.18 |
| Spark와 RDD (0) | 2023.08.18 |