
RDD의 저장
RDD 저장에 대한 개념은 RDD가 메모리에 저장되거나 디스크에 저장될 수 있다는 것을 의미합니다. 저장 방법은 다음과 같이 세분화됩니다:
RDD 스토리지 레벨
1. 메모리 저장 (In-Memory Storage)
- MEMORY_ONLY: RDD를 JVM(Java Virtual Machine)의 힙 메모리에만 저장합니다. 이 방식은 가장 빠른 읽기 속도를 제공하지만, 메모리 용량이 제한적이기 때문에 모든 데이터를 저장할 수 없을 경우 일부 데이터를 잃어버릴 수 있습니다.
- MEMORY_AND_DISK: RDD의 일부를 메모리에, 나머지를 디스크에 저장합니다. 메모리 용량을 초과할 경우, 초과하는 데이터는 디스크에 저장됩니다. 이 방법은 메모리 용량을 초과하는 데이터를 처리할 때 유용하지만, 디스크 접근에 따른 성능 저하가 발생할 수 있습니다.
2. 디스크 저장 (Disk Storage)
- DISK_ONLY: RDD를 디스크에만 저장합니다. 이 방식은 데이터를 영구적으로 저장할 수 있으며, 메모리 제한에 구애받지 않지만, 메모리 기반 저장보다 느립니다.
3. 기타 저장 옵션
- MEMORY_ONLY_SER (Serialization): 데이터를 직렬화된 형태로 메모리에 저장합니다. 이 방식은 메모리 사용량을 줄이지만, 데이터 접근 시 역직렬화 과정이 필요하여 성능 저하가 발생할 수 있습니다.
- MEMORY_AND_DISK_SER: 직렬화된 데이터를 메모리와 디스크에 저장합니다. 메모리 용량 초과 시 직렬화된 데이터를 디스크에 저장합니다.
RDD를 저장할 때는 데이터 접근 속도, 메모리 사용량, 데이터 복구 용이성 등을 고려하여 적절한 저장 전략을 선택해야 합니다. Spark는 이러한 요구 사항에 따라 다양한 저장 수준을 제공하여, 개발자가 애플리케이션의 요구 사항에 맞게 최적화할 수 있도록 지원합니다.
RDD 스토리지 레벨 플래그
스토리지 레벨 플래그는 Apache Spark에서 RDD(Resilient Distributed Dataset) 또는 데이터셋을 저장할 때 사용되는 메모리 관리 및 데이터 저장 전략을 정의합니다. 이 플래그들은 Spark가 데이터를 어떻게 저장할지, 메모리와 디스크를 어떻게 활용할지 결정하는 데 도움을 줍니다. 다양한 스토리지 레벨 플래그를 사용함으로써, 애플리케이션의 성능을 최적화하고, 자원 사용을 효율적으로 관리할 수 있습니다.
스토리지 레벨은 다음과 같은 플래그로 구성됩니다:
1. MEMORY_ONLY
- 데이터를 JVM의 메모리에만 저장합니다. 데이터에 대한 빠른 접근이 가능하지만, 메모리 용량이 제한적일 수 있습니다.
from pyspark import SparkContext, StorageLevel
sc = SparkContext("local", "StorageLevelExample")
rdd = sc.parallelize(range(1, 10000))
cachedRDD = rdd.persist(StorageLevel.MEMORY_ONLY)
print(cachedRDD.count())2. MEMORY_AND_DISK
- 데이터의 일부를 메모리에, 나머지를 디스크에 저장합니다. 메모리 용량이 부족할 때 디스크를 사용하여 데이터를 저장하므로, 메모리 내에서 처리할 수 없는 큰 데이터셋에 유용합니다.
cachedRDD = rdd.persist(StorageLevel.MEMORY_AND_DISK)
print(cachedRDD.count())3. DISK_ONLY
- 모든 데이터를 디스크에만 저장합니다. 메모리 사용량을 최소화할 수 있지만, 디스크 접근 속도가 느린 단점이 있습니다.\
cachedRDD = rdd.persist(StorageLevel.DISK_ONLY)
print(cachedRDD.count())4. MEMORY_ONLY_SER (Serialization)
- MEMORY_AND_DISK_SER 스토리지 레벨은 데이터를 직렬화하여 메모리에 저장합니다.
- 메모리 용량을 초과하는 경우, 데이터는 디스크에 저장됩니다. 이 방식은 메모리 사용량을 줄이면서도, 메모리 내에 저장할 수 없는 데이터에 대해 디스크를 백업 저장소로 사용할 수 있게 해줍니다.
- 데이터를 직렬화함으로써 메모리 효율성을 높일 수 있지만, 데이터 접근 시 역직렬화가 필요하여 성능 오버헤드가 발생할 수 있습니다.
cachedRDD = rdd.persist(StorageLevel.MEMORY_ONLY_SER)
print(cachedRDD.count())5. MEMORY_AND_DISK_SER
- 직렬화된 형태의 데이터를 메모리와 디스크에 저장합니다. 메모리 용량을 초과하는 데이터는 디스크에 저장됩니다. 메모리 사용량을 줄이면서도, 데이터를 안정적으로 관리할 수 있습니다.
cachedRDD = rdd.persist(StorageLevel.MEMORY_AND_DISK_SER)
print(cachedRDD.count())추가 플래그:
- OFF_HEAP: 데이터를 JVM의 힙 메모리가 아닌, 네이티브 메모리에 저장합니다. 이 옵션은 고급 사용자를 위해 제공되며, 추가 설정이 필요할 수 있습니다.
# 주의: 오프힙 스토리지를 사용하기 위해서는 추가적인 설정이 필요할 수 있습니다.
cachedRDD = rdd.persist(StorageLevel.OFF_HEAP)
print(cachedRDD.count())
RDD 캐싱
Apache Spark에서 persist()와 cache() 메서드는 RDD(Resilient Distributed Dataset)나 DataFrame을 메모리에 저장하여 재사용함으로써 데이터 처리 작업의 효율성을 향상시키는 데 사용됩니다. 이 두 메서드는 데이터를 캐싱하여 재계산 없이 여러 데이터 변환 작업이나 액션에서 재사용할 수 있도록 해줍니다. 이는 특히 반복적인 연산이나 반복적인 쿼리 처리에서 큰 성능 이점을 제공합니다.
persist()
persist() 메서드는 데이터를 캐싱할 때 사용자가 스토리지 레벨을 명시적으로 지정할 수 있게 해줍니다. 스토리지 레벨에는 MEMORY_ONLY, MEMORY_AND_DISK, DISK_ONLY, MEMORY_ONLY_SER, MEMORY_AND_DISK_SER 등이 있으며, 사용자는 이 중에서 데이터의 저장 방식을 선택할 수 있습니다. 이를 통해 메모리 사용량, 처리 속도, 디스크 사용량 등을 애플리케이션의 요구 사항에 맞게 최적화할 수 있습니다.
rdd.persist(StorageLevel.MEMORY_AND_DISK)
cache()
cache() 메서드는 persist() 메서드의 특별한 경우로, 데이터를 메모리에만 저장합니다. 이 메서드를 사용할 때는 추가적인 스토리지 레벨을 지정할 수 없으며, 기본적으로 MEMORY_ONLY 스토리지 레벨이 사용됩니다. cache()는 사용이 간편하며, 데이터를 빠르게 접근해야 하지만, 메모리 용량을 초과할 위험이 낮은 경우에 적합합니다.
rdd.cache()
차이점
- 유연성: persist() 메서드는 다양한 스토리지 레벨을 제공하여, 메모리, 디스크, 직렬화 사용, 오프힙 저장 등의 옵션을 선택할 수 있게 해줍니다. 반면, cache() 메서드는 MEMORY_ONLY 스토리지 레벨을 사용하여 데이터를 메모리에만 캐싱합니다.
- 용도: cache()는 사용이 간단하며, 대부분의 경우에서 데이터를 빠르게 재사용할 수 있는 효율적인 방법을 제공합니다. persist()는 더 세밀한 제어가 필요하거나 특정 스토리지 전략이 요구되는 고급 사용 사례에 적합합니다.
RDD 체크포인트
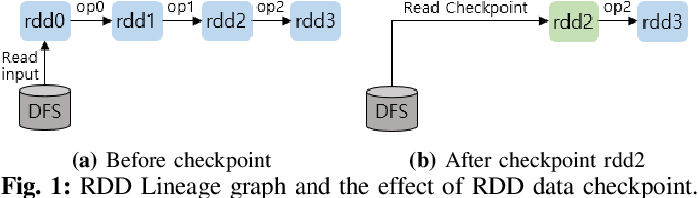
RDD 체크포인트는 Apache Spark에서 장애 복구를 위해 사용되는 메커니즘 중 하나입니다. 체크포인트는 RDD의 상태를 안정적인 저장소(예: 디스크)에 저장하여, 계산이 중간에 실패할 경우 해당 상태를 복구하는 데 사용됩니다. 이는 Spark의 리니지(lineage, RDD의 변환 과정과 의존성 정보를 추적하는 기능)를 통한 복구 방식을 보완하는 기능입니다.
RDD 체크포인트의 필요성
Spark는 기본적으로 리니지를 사용해 오류 발생 시 데이터를 재계산함으로써 복구를 수행합니다. 하지만, 긴 변환 과정을 거친 RDD에 대해서는 리니지가 매우 길어질 수 있으며, 이는 재계산 시간을 상당히 늘릴 수 있습니다. 체크포인트를 사용하면, 이러한 긴 리니지를 짧게 만들어 재계산 시간을 단축시킬 수 있습니다.
체크포인트 사용 방법
- 체크포인트 디렉토리 설정: 체크포인트를 저장할 디렉토리를 설정해야 합니다. 이는 HDFS와 같은 안정적인 파일 시스템 경로일 수 있습니다.
- 체크포인트 적용: RDD에 대해 checkpoint() 메서드를 호출하여 체크포인트를 적용합니다.
from pyspark import SparkContext
sc = SparkContext("local", "CheckpointExample")
# 체크포인트 디렉토리 설정
sc.setCheckpointDir("/path/to/checkpointDir")
rdd = sc.parallelize(range(1, 100))
# RDD에 체크포인트 적용
rdd.checkpoint()
# 체크포인트가 실제로 파일 시스템에 저장되려면 액션이 실행되어야 합니다.
rdd.count()
주의사항
- 체크포인트는 리니지 정보를 제거하고, 해당 RDD를 파일 시스템에 저장합니다. 따라서, 체크포인트 후에 원본 데이터에 대한 참조가 필요하다면 주의해야 합니다.
- 체크포인트는 디스크 I/O를 발생시키므로, 사용 시에는 성능 저하를 고려해야 합니다.
- 체크포인트는 실행 시점에서 즉시 발생하는 것이 아니라, RDD에 액션이 호출될 때 실제로 수행됩니다.
- 스토리지 옵션 무관: RDD나 DataFrame의 메모리, 디스크, 직렬화 옵션 등 스토리지 레벨 설정과는 별개로, 체크포인트는 항상 디스크에 데이터를 저장합니다.
체크포인트 함수
1. setCheckpointDir
- 용도: 체크포인트 파일을 저장할 디렉토리를 설정합니다.
- 설명: 체크포인트를 사용하기 전에 SparkContext를 통해 체크포인트 파일을 저장할 디렉토리를 지정해야 합니다. 이 디렉토리는 일반적으로 HDFS와 같은 분산 파일 시스템 경로입니다.
sc.setCheckpointDir("hdfs://path/to/checkpointDir")
2. checkpoint
- 용도: 특정 RDD에 체크포인트를 적용합니다.
- 설명: 이 메서드를 호출하면 해당 RDD가 체크포인트 대상이 됩니다. 실제 체크포인트 파일은 RDD에 대한 액션이 호출될 때 생성됩니다.
rdd.checkpoint()
3. isCheckpointed
- 용도: RDD가 체크포인트 되었는지 여부를 확인합니다.
- 설명: 이 메서드는 RDD가 성공적으로 체크포인트 되었는지의 여부를 반환합니다. 체크포인트가 완료되면 True를, 그렇지 않으면 False를 반환합니다.
rdd.isCheckpointed()
4. getCheckpointFile
- 용도: 체크포인트 파일의 경로를 얻습니다.
- 설명: RDD가 체크포인트를 통해 저장된 경우, 해당 체크포인트 파일의 경로를 반환합니다. 체크포인트가 아직 수행되지 않았거나 실패한 경우 None을 반환할 수 있습니다.
rdd.getCheckpointFile()
사용예시
from pyspark import SparkContext
sc = SparkContext("local", "CheckpointExample")
sc.setCheckpointDir("/path/to/checkpointDir")
rdd = sc.parallelize(range(1, 100))
rdd.checkpoint()
# 액션을 호출하여 체크포인트를 실제로 수행
rdd.count()
if rdd.isCheckpointed():
print("RDD is checkpointed.")
print("Checkpoint file: {}".format(rdd.getCheckpointFile()))
체크포인트 기능은 특히 복잡한 변환 과정을 거친 RDD에 대해 장애 복구와 성능 최적화의 측면에서 유용하게 사용됩니다. 체크포인트를 설정할 때는 해당 작업이 추가적인 디스크 I/O를 발생시키므로, 성능에 미치는 영향을 고려하여 적절한 타이밍에 사용해야 합니다.
체크포인트 프로세스가 실행될 때, 지정된 RDD의 현재 상태가 안정적인 저장소에 저장됩니다. 이 저장소는 일반적으로 HDFS(Hadoop Distributed File System)와 같은 분산 파일 시스템입니다. 체크포인트를 통해 저장된 데이터는 Spark 클러스터의 노드 장애 발생 시에도 복구가 가능하며, 라인리지가 재계산될 필요 없이 직접 접근할 수 있습니다.
체크포인트의 주요 이점:
- 장애 복구: 데이터 처리 중에 발생할 수 있는 장애에 대비해, 중간 결과를 디스크에 저장함으로써 데이터를 보호합니다. 이를 통해, 작업 실패 시 라인리지를 완전히 다시 계산하는 대신 체크포인트로부터 데이터를 빠르게 복구할 수 있습니다.
- 성능 최적화: 복잡한 라인리지 체인은 작업 재시작 시 많은 재계산을 요구할 수 있습니다. 체크포인트를 사용하면, 이러한 라인리지를 단축시켜 재계산 시간을 줄일 수 있습니다.
체크포인트의 작동 방식:
- 체크포인트를 실행하기 전에, SparkContext를 사용하여 체크포인트 파일을 저장할 디렉토리를 설정합니다.
- RDD에 checkpoint() 메소드를 호출하여 체크포인트를 설정합니다.
- 실제 체크포인트는 RDD에 대한 액션(예: count(), collect())이 호출될 때 수행됩니다. 이때 RDD의 데이터가 지정된 디렉토리에 저장됩니다.
- 한 번 체크포인트된 RDD는 라인리지 정보가 제거되고, 필요할 경우 디스크에서 직접 데이터를 읽어들입니다.
'Tools > Spark' 카테고리의 다른 글
| Spark 다양한 데이터 타입 다루기 (0) | 2024.05.08 |
|---|---|
| Spark SQL과 Hive를 통한 데이터 처리 (0) | 2024.03.26 |
| Spark 브로드캐스트 변수(Broadcast Variables)와 어큐뮬레이터(Accumulators) (0) | 2024.03.21 |
| Spark RDD 연산 예제 모음 (0) | 2024.03.13 |
| Spark RDD 연산 주요 개념 (0) | 2024.03.11 |